Avoiding Accidents Using Computer Vision
Background of the Problem
As per the Road Accident Report for 2019, a total number of 449,002 accidents took place in the country during the calendar year 2019 leading to 151,113 deaths and 451,361 injuries. Due to road accidents, every year nearly 1 out of 20,000 people lose their lives, and 12 out of 70,000 individuals face serious injuries in India. A lot of research has been done for pedestrian detection, vehicle detection, and animal detection on roads. In this blog, we have discussed various advanced object detection algorithms that can be used for accident avoidance.
Different Methods
1) Histogram of Oriented Gradients (HOG)
The histogram of oriented gradients (HOG) is a feature descriptor used in computer vision and image processing for the purpose of object detection and image classification. . The idea behind HOG is to extract features from an image into a single-dimensional vector, and feed it into a classification algorithm like a Cascade classifier or a Support Vector Machine that will assess whether a pedestrian (or any other object ) is present in a region or not.

[Image_Ref:
In the histogram of oriented feature descriptor, the distribution of directions of gradients i.e oriented gradients are used as features for the given image. Gradients are nothing but the x and y derivatives of the image. of an image. Gradients are useful because the magnitude of gradients is large around edges and corners. Edges and corners (high-frequency regions) contain a lot more information about object shape than flat regions. which is an important characteristic.
1.Calculate the Gradient Images
2. Compute the HOG
3. Block normalization
4. Feeding the vector into SVM
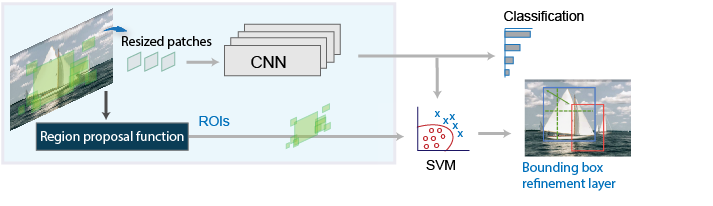
2) Region-based Convolutional Neural Network( R-CNN)
Regions with convolutional neural networks or R-CNN is a two-stage object detection algorithm. It combines rectangular region proposals with convolutional neural network(CNN) features. In the first stage, the algorithm identifies regions in the given image that might contain an object, and in the second stage, it classifies the objects in each region.
The first step is to Generate region proposals( regions in the given image that might contain an object) using an algorithm such as Edge Boxes or a selective search algorithm. Selective search algorithms generate 2000 region proposals. The selective Search algorithm works in the following manner. First, it Generates initial sub-segmentation, then it uses a greedy algorithm to recursively combine similar regions, and finally, it uses the generated regions to produce the final candidate region proposals.

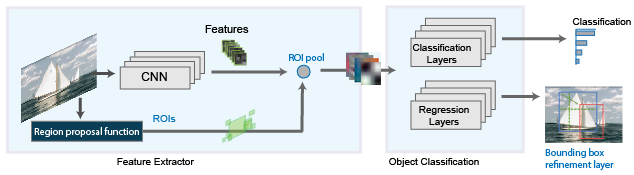
3) FastRCNN
To solve some of the drawbacks of R-CNN and to build a faster object detection algorithm the authors of the R-CNN paper proposed a new modified algorithm which is called Faster R-CNN. Unlike the R-CNN detector, which works on the cropped and resized regional proposals, the Fast R-CNN detector processes the entire image.

[ Image ref: https://www.mathworks.com/help/vision/ug/fast.png ]
Thus it generates a convolutional feature map. From the convolutional feature map, The algorithm identifies the region of proposals and warp them into squares. Then it reshapes them into a fixed size by using an RoI pooling layer so that it can be fed into a fully connected layer. And from the RoI feature vector, uses a softmax layer to predict the class of the proposed region. The reason the Fast R-CNN algorithm is faster than the R-CNN algorithm is, In fast R CNN we don’t have to feed 2000 region proposals to CNN every time. Instead, a feature map is generated by performing a single convolution operation per image.
4) SingleShot Multibox Detector (SSD)
It was released in 2016, scoring over 74% mean average precision (mAP) at 59 frames per second on standard datasets such as PascalVOC and COCO. The name of this architecture is being divided into :

[image_ref_:https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab]
multibox_loss = confidence_loss + alpha * location_loss

[image_ref_:https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab]
In this for the contribution of the location loss, the alpha term is used. Also, MultiBox starts with the priors as predictions which attempt and help to regress closer to the ground truth bounding boxes.
5) You Only Look Once (YOLO)
YOLO trains on full images and optimizes directly for detection performance. YOLO is extremely fast. Unlike sliding window and regional-based CNN, YOLO sees the entire image during training and test time. Also, YOLO makes less than half the number of background errors compared to Fast R-CNN. When trained and tested on images, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin. Below diagram shows the detection process using YOLO for preventing accident of car :

{kind=link}
{kind=link}

Conclusion
In this paper, We have described and discussed advanced object detection algorithms such as HOG(Histogram of oriented Gradients) Cascade, Regions with convolutional neural networks or R-CNN, Fast R-CNN, Single Shot Multibox Detector (SSD), and You Only Look Once (YOLO). These algorithms need a good amount of data ( of images ) which is taken in different real/realistic scenarios like time of the day, type of area(for example urban, rural, forest, etc. ), quality of the camera, etc.
Computer vision is one of the fastest-growing fields. With the increase in the availability of data and deep learning research quality, the object detection algorithms will become more accurate and faster.
References
[2] https://morth.nic.in/road-accident-in-india
[3] Girshick, R., J. Donahue, T. Darrell, and J. Malik. "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation." CVPR '14 Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Pages 580-587. 2014 [4] Zitnick, C. Lawrence, and P. Dollar. "Edge boxes: Locating object proposals from edges." Computer Vision-ECCV. Springer International Publishing. Pages 391-4050. 2014. [5]https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8832160
[6]https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab
[7]https://medium.com/egen/region-proposal-network-rpn-backbone-of-faster-r-cnn-4a744a38d7f9
[8]https://www.hindawi.com/journals/jat/2020/9194028/
Author behind this post are : Nisarg Mehta, Vivek Mankar, Addvija Medhekar, Amol Pawar, Umang Pathrabe
PLEASE COMMENT YOUR THOUGHTS IN THE COMMENT SECTION. HOPE YOU ALL LIKED OUR BLOG
Comments
Post a Comment